Why Faker Isn't Enough for Document AI Training
If you've ever trained a document extraction model, you've probably started with Faker. Generate some names, addresses, and SSNs. Drop them into a template. Feed the PDFs to your model.
It works — until it doesn't.
The Problem With Random Fields
Faker generates each field independently. A random name. A random address. A random employer. A random income. None of these values have any relationship to each other.
That's fine for populating a database table for unit tests. It's not fine for training a model that needs to understand documents.
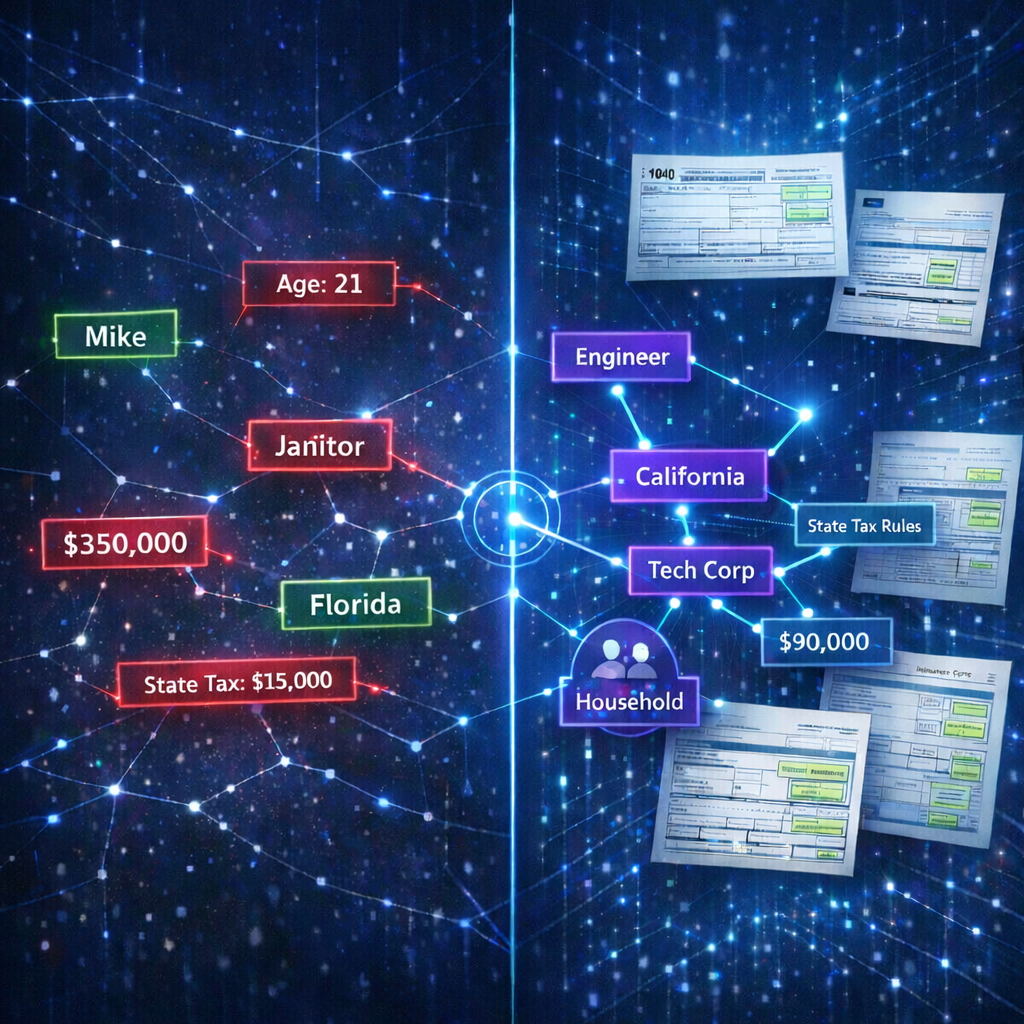
Consider a W-2 form. The employer name, employer address, employer EIN, wages, and tax withholdings are all related. A teacher at a public school in rural Mississippi doesn't earn $850,000. A sole proprietor doesn't have federal tax withholdings from an employer. A California address shouldn't appear with a Texas state tax filing.
When your training data contains these contradictions, your model learns the wrong patterns. It learns that any combination of values is valid. In production, when it encounters a real document with coherent data, it has no basis for confidence.
Cross-Field Dependencies Matter
Real documents have structure. Not just visual structure (where fields appear on the page) but semantic structure (how field values relate to each other).
A few examples across common form types:
- W-2: Wages in Box 1 should be greater than or equal to Social Security wages in Box 3. Federal tax withheld in Box 2 should be a plausible percentage of wages.
- 1040: Adjusted gross income should be consistent with the W-2s attached. Filing status should match the number of dependents claimed.
- CMS-1500: The diagnosis codes should be consistent with the procedure codes. The service facility address should be a real medical facility type.
- Insurance applications: The applicant's age, occupation, and coverage amount should be statistically plausible together.
Faker can't model any of this. It doesn't know what a W-2 is. It doesn't know that Box 1 and Box 3 are related. It just generates random numbers.
What Document AI Models Actually Need
Modern document extraction models — whether you're using Google Document AI, Azure AI Document Intelligence, AWS Textract, or training a custom model — need training data that's:
- Structurally coherent: Field values that make sense together
- Statistically realistic: Distributions that match the real world
- Visually diverse: Different fonts, alignments, scan qualities, and handwriting styles
- Labeled with ground truth: Bounding boxes and field mappings for every value on every page
Faker gives you none of these. You get random strings placed into templates, with no ground truth annotations and no structural validity.
The Simulation Approach
SymageDocs takes a fundamentally different approach. Instead of generating random fields, it simulates people.
Each synthetic identity starts as a complete life simulation: demographics determine occupation, occupation determines income, income determines tax brackets, household composition determines filing status and dependents. Every downstream value is derived from this coherent model.
When SymageDocs fills a W-2 for this person, the wages, tax withholdings, employer information, and state filing details are all internally consistent — because they were all derived from the same underlying identity.
When it fills a 1040, the numbers add up. The W-2 income matches the 1040 line items. The deductions are plausible for the person's income level and filing status.
This is the difference between random data and realistic data.
Ground Truth Included
Beyond structural coherence, SymageDocs solves the labeling problem. Every filled document includes:
- Pixel-perfect bounding boxes for every field value
- Structured JSON mapping each field to its value and position
- Multiple output formats (typed, handwritten) from the same underlying data
This means you go from "I need training data" to "I'm training my model" without spending weeks on manual annotation.
When Faker Is Still the Right Choice
To be clear: Faker is an excellent tool for what it was designed for. If you're populating a test database, seeding a development environment, or generating mock API responses, Faker is fast, flexible, and well-supported.
But if you're training models that need to understand documents — their visual layout, their semantic structure, and the relationships between fields — you need training data that reflects that structure.
Getting Started
SymageDocs offers 200 free credits to start. Generate a batch of synthetic W-2s or CMS-1500 forms, compare them to what Faker would produce, and see the difference in your model's performance.
The gap between "random data on a form template" and "coherent synthetic documents" is the gap between a model that sort-of works and one you can deploy with confidence.
Ready to generate synthetic document data?
Start with 200 free credits. No credit card required.
Start for Free